Data Science Part 2: Training Deep Learning Models with PowerEdge
- Nomuka Luehr

- Jul 30, 2022
- 5 min read
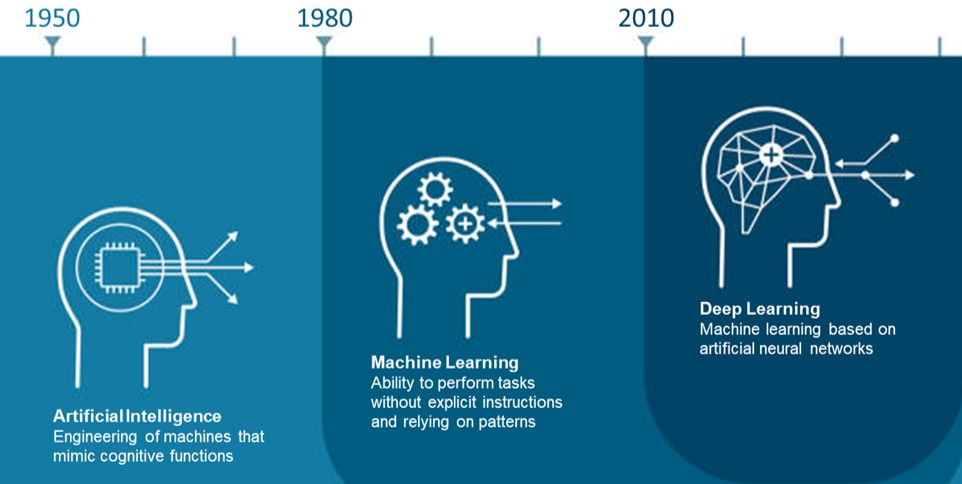
Are you smarter than an AI? Well, it is widely agreed upon that AI intelligence is currently on par with that of adult humans. This means that we and machines perform comparably on tasks that require skills like logical reasoning, problem-solving, and abstract thinking. This long-awaited achievement for AI development is primarily attributed to Deep Learning (DL) advancements.
What is Deep Learning?
Unlike other machine learning (ML) methods, DL uses a more complex structure of layered algorithms called neural networks that analyze data with a logical design similar to how our brains draw conclusions and learn over time. If you're interested in reading more about the different types of neural networks and how they work, check out this article. While other ML methods rely on engineers to adjust and increase the accuracy of their models, neural networks can learn from previous right and wrong predictions by employing a process called backpropagation where they manipulate the weights and biases of their algorithms until the correct output occurs. DL's high accuracy and less need for human intervention ultimately means that we can tackle more complex use cases with better outcomes.
Although it requires less maintenance over time, DL typically requires more computing power than other ML methods. We may take it for granted but mimicking the billions of interconnected cells within our brain that work parallelly to take in new data, recognize patterns, and make decisions is no easy feat for computers. DL requires vast amounts of data and complex software simulations to ensure consistently accurate results. Nevertheless, companies are more than willing to invest in the necessary hardware and software systems, as continued AI augmentation through DL is expected to generate trillions in business value through more effective and reliable methods of data analysis and decision making.
How can organizations make the best use of Deep Learning?
Optimal application of DL techniques has already enabled great successes in many fields, such as computer vision through object detection, commerce through recommendations, and autonomous driving through combining a multitude of techniques. However, reaping such rewards is challenging without the right tools. DL workloads are not simple to carry out, and related system components must be carefully selected and tuned for each unique use case. Therefore, organizations are faced with many complex choices, including those related to data, software, performance analytics, and infrastructure components—each with varying impact on accuracy, ease and time of deployment, and business impact.
With these pain points in mind, I thought we'd take some time to explore how engineers can use available benchmarking tools to improve the efficiency of their models, particularly when it comes to choosing and sizing the appropriate infrastructure elements. Before we check out the components that are tasked with running these demanding workloads, let's explore the process of implementing a DL model.
How is Deep Learning implemented?
Just like how we attend school, DL models must undergo training on sample data sets to discover patterns and modify their algorithms for the desired output before tackling new instances. The training phase involves several iterations and a substantial amount of data, which usually requires multi-core CPUs or GPUs to accelerate performance for high accuracy. After training, the model moves onto inferencing, where it can be deployed on FPGAs, CPUs, or GPUs to perform its specific business function or task.
As DL models cycle between training and inferencing to continuously adapt the model to changes in data, ensuring the efficiency of both phases is critical to the system's overall performance. In this blog, we'll explore how to evaluate and choose system components to help enhance the efficiency of the DL training phase. Stay tuned for the next blog when we explore similar methods for ensuring optimal performance for DL inferencing!

How can I pick the right infrastructure tools to train my Deep Learning model?
Optimizing a platform for DL requires the contemplation of many variables as it allows for a range of statistical, hardware, and software optimizations that can significantly alter the model's learning processes, training time, and accuracy. Additionally, the software and hardware systems available are so diverse that comparing their performance is difficult even when using the same date, code, and hyperparameters.
Thankfully, there is MLPerf, an industry-standard performance benchmark system for ML that overcomes related challenges to help fairly evaluate the performance of different DL systems. To do so, MLPerf provides an agreed-upon process for measuring how quickly and efficiently different types of accelerators and systems can train a given model. MLPerf is especially useful and has gained widespread popularity for providing accurate benchmarking results for multiple DL domains, including image classification, NLP, object detection, and more:

For each given domain, MLPerf will measure performance by assessing and comparing the total amount of time that it takes to train a neural net model for a given domain from the list above to reach target accuracy. To help data scientists pick the appropriate infrastructure components that will achieve their DL goals, Dell submitted the following servers for benchmarking across various domains:

Here's a quick glimpse at the benchmarking results of the various Dell EMC systems for the Natural Language Processing (NLP) domain, a field of ML that's focused on interpreting, responding, or manipulating (i.e., translating) human language. Click here to find benchmarking results for all available domains.

As you can see, varying the server and system setup, processor type and count, and accelerator type and count can significantly impact a model's required training time despite using the same software and dataset.
As you explore the MLPerf benchmark results, I recommend keeping the following two things in mind:
GPUs and FPGAs are arguably the best-known types of accelerators for DL. Originally designed for the complex calculations of graphics processing, GPUs quickly train Deep Learning models as well. FPGAs were first used in networking in telecommunications and are thus ideal for inferencing tasks on already trained models, and something we will explore further in upcoming blogs.
While using superior accelerators is beneficial, the impact on training times and scaling behavior varies between different domains and models. For example, larger GPU counts are still useful but do not scale performance at a linear rate for domains like Translation and Recommendation. Therefore, in order to pick the appropriate server and number of GPUs, it is highly useful to have a comprehensive understanding of the models and domains being used.
What's next?
This blog explored how data scientists can use MLPerf Benchmarks to optimize their DL training process. Stay tuned for Data Science Part 3 as we move on from training to discover how to choose the right infrastructure components for optimal DL inference performance!
Want to know more about Deep Learning? Check out the resources below
Opinions expressed in this article are entirely my own and may not be representative of the views of Dell Technologies.



Comments